Section 1: The Fundamental Challenge of Noise in Magnetic Resonance Imaging
Magnetic Resonance Imaging (MRI) stands as a cornerstone of modern medical diagnostics, offering unparalleled soft-tissue contrast without the use of ionizing radiation. However, the physical process of acquiring MR signals is inherently susceptible to noise, a phenomenon that fundamentally constrains image quality and diagnostic utility. Noise manifests as random fluctuations in pixel intensity, which can obscure fine anatomical details, mimic or mask pathology, and corrupt quantitative measurements derived from the images. The central challenge in interpreting MRI data, particularly in advanced applications like functional MRI (fMRI), is to discern whether an observed signal change is a true reflection of underlying physiology or merely a random fluctuation caused by noise. Addressing this challenge through effective denoising is not a cosmetic exercise; it is a critical step toward enabling faster, higher-resolution, and more quantitatively accurate imaging. To develop and evaluate sophisticated denoising algorithms, a foundational understanding of the physical origins and statistical characteristics of MRI noise is paramount.
1.1. The Physics of Noise: Thermal and Physiological Sources
Noise in MRI is a broad term for any process that adds spurious fluctuations to the measured nuclear magnetic resonance (NMR) signal. These fluctuations arise from multiple sources within the scanner hardware, the patient's body, and the surrounding environment. They can be broadly categorized into thermal, physiological, and system-related sources.
Thermal Noise, often referred to as Johnson-Nyquist noise, is a fundamental and inescapable source of signal degradation. It originates from the random thermal motion of electrons within the imaging hardware and the patient's body, which induce stray electrical currents in the radiofrequency (RF) detector coil. The primary contributors to thermal noise are the electrical resistance of the RF coil itself, dielectric and inductive losses within the patient's tissues (the sample), and the electronic components of the preamplifier that first receives the MR signal. This noise is characteristically "white," meaning its power spectrum is flat, and it corrupts all frequencies of the acquired signal uniformly. The magnitude of this noise is proportional to the square root of the receiver bandwidth; a wider bandwidth allows more noise to enter the system for each voxel.
Physiological Noise stems from the subject's own biological processes. While thermal noise is often the primary concern in static, high-resolution anatomical imaging, physiological noise frequently becomes the dominant source of error in dynamic imaging sequences like fMRI or cardiac cine MRI. Its sources include the pulsatile flow of blood related to the cardiac cycle, patient respiration which causes movement of the chest and abdomen, and both voluntary and involuntary patient motion. Unlike the random, unstructured nature of thermal noise, physiological noise is often quasi-periodic and spatially structured, making it particularly challenging to model and remove.
System-Related Noise encompasses unwanted signals generated by the MRI scanner hardware during operation. In modern superconductive scanners, a helium pump used for the refrigeration system creates a constant, low-frequency rhythmic "thump-thump" sound that is present even when not actively scanning. Much more prominent are the extremely loud noises produced during the scan itself. These sounds, which can reach levels of 110-120 dB—comparable to a jackhammer—are caused by the rapid switching of large electrical currents through the gradient coils. These currents induce powerful Lorentz forces that cause the coils to vibrate mechanically, radiating sound waves. Each pulse sequence has a unique acoustic signature based on its specific gradient waveform pattern. While this audible noise is primarily a patient comfort and safety issue, the underlying mechanical vibrations and electromagnetic interference can also contribute to image degradation.
A crucial connection exists between the audible system noise and the statistical image noise. The most aggressive pulse sequences, such as Echo-Planar Imaging (EPI), which are used for fast acquisitions like fMRI and diffusion-weighted imaging (DWI), involve the most rapid and intense gradient switching and are therefore the loudest. These same fast sequences inherently acquire less signal per unit time. The Signal-to-Noise Ratio (SNR) of an image is fundamentally proportional to the square root of the total acquisition time. Consequently, the very pulse sequence designs that create a loud and uncomfortable environment for the patient are also those that produce images with the lowest intrinsic SNR, making them most susceptible to corruption by thermal and physiological noise.
1.2. Statistical Characterization: From Gaussian to Rician Distributions
Understanding the statistical distribution of noise is critical for designing and validating denoising algorithms. The raw MRI signal is acquired in the frequency domain (k-space) using a quadrature detector, which measures two orthogonal components of the signal: a real part and an imaginary part. The thermal noise in each of these channels can be accurately modeled as having a zero-mean Gaussian distribution. The image is then reconstructed from this complex-valued k-space data via a two-dimensional Fourier transform (2DFT). Because the Fourier transform is a linear and orthogonal operation, it preserves the Gaussian characteristics of the noise. The result is that in the reconstructed complex-valued image, the noise in both the real and imaginary components remains Gaussian-distributed with a uniform variance across the entire field of view.
However, the vast majority of clinical MRI images are not complex-valued. To avoid phase-related artifacts, clinicians typically view magnitude images, which are generated by calculating the magnitude of each complex-valued pixel: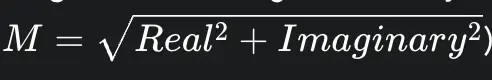
This seemingly simple step is a non-linear transformation that fundamentally alters the statistical properties of the noise.
In regions of the image where there is a genuine NMR signal (i.e., within anatomical tissue), the noise in the resulting magnitude image no longer follows a Gaussian distribution. Instead, it is governed by a Rician distribution. The probability density function of the Rician distribution is given by: 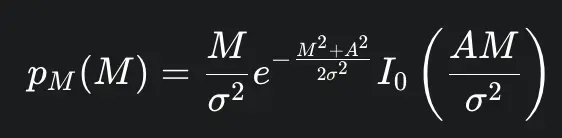
where M is the measured pixel intensity, A is the true underlying signal amplitude, σ is the standard deviation of the original Gaussian noise in the real and imaginary channels, and I0 is the modified Bessel function of the first kind of order zero. The Rician distribution is skewed, and its shape depends on the local SNR, defined as
A/σ. At high SNR (where A≫σ), the Rician distribution approaches a Gaussian distribution. However, at low SNR (e.g., SNR < 2), the distribution is distinctly non-Gaussian and positively biased, meaning the measured signal is always higher than the true signal.
In regions of the image with no NMR signal, such as the background air outside the patient, the true signal A is zero. In this special case, the Rician distribution simplifies to a Rayleigh distribution. This is a critical distinction, as a common but flawed practice is to estimate image noise by measuring the standard deviation in a background region. This only characterizes the Rayleigh noise and does not accurately reflect the Rician noise present within the tissue of interest.
This statistical reality has profound implications. Many generic image denoising algorithms, including a significant number of early deep learning models, are designed and trained assuming simple additive white Gaussian noise (AWGN). Applying such a model to a magnitude MRI image, which contains signal-dependent Rician noise, represents a fundamental model mismatch. This can lead to suboptimal performance, the introduction of bias, and poor preservation of detail, particularly in low-SNR regions where the Rician effects are most pronounced. This mismatch is a primary driver for the development of more sophisticated, domain-specific AI models that can either operate directly on the complex-valued data before the magnitude transform or are explicitly designed to handle the Rician distribution.
1.3. The Impact of Noise on Diagnostic Quality and Quantitative Analysis
The ultimate goal of MRI is to provide clear images for accurate diagnosis and reliable quantitative analysis. Noise directly undermines this goal by degrading image quality and reducing the fundamental measure of that quality: the Signal-to-Noise Ratio (SNR). A low SNR can impede a radiologist's ability to visually interpret images and reduce the sensitivity for detecting subtle pathologies.
The SNR of an MRI scan is not a fixed property but is influenced by a complex interplay of factors related to the hardware, acquisition protocol, and patient:
Magnetic Field Strength (B0): A primary motivation for developing high-field MRI systems (e.g., 3T, 7T) is that the equilibrium magnetization (M0), which is the source of the MR signal, increases with B0. This directly leads to a higher potential SNR.
Pulse Sequence and Contrast: The choice of pulse sequence parameters, such as repetition time (TR) and echo time (TE), manipulates the transverse magnetization to generate different tissue contrasts (e.g., T1-weighted, T2-weighted). These manipulations inherently affect the signal magnitude at the time of acquisition and thus the resulting SNR.
Acquisition Time and Averaging: SNR improves with the square root of the total time spent collecting data. This can be increased by using longer acquisition windows or by averaging multiple acquisitions (increasing the Number of Excitations, or NEX). This creates the central trade-off in clinical MRI: higher quality images take longer to acquire, increasing costs and the likelihood of patient motion artifacts.
Spatial Resolution (Voxel Volume): Achieving high spatial resolution requires the use of small voxels. However, the signal from a voxel is proportional to its volume. Therefore, smaller voxels generate less signal, resulting in lower SNR.
Parallel Imaging: Techniques like GRAPPA and SENSE are indispensable for accelerating MRI scans. They work by undersampling k-space and using the distinct spatial sensitivity profiles of multiple receiver coils to reconstruct the full image. While this dramatically reduces scan time, it comes at the cost of reduced SNR. The reconstruction process amplifies noise, an effect quantified by the "g-factor," and can introduce structured, non-uniform noise patterns into the final image.
Beyond simple visual degradation, noise has a pernicious effect on advanced image processing and quantitative analysis. In Diffusion Tensor Imaging (DTI), noise propagates into the estimated tensors, corrupting measures of tissue microstructure like fractional anisotropy. For high b-value DWI, which is critical for probing fine microstructural details, the signal is heavily attenuated, and the remaining low signal can be completely overwhelmed by noise, biasing the derived measurements. Similarly, noise makes subsequent processing steps like image registration more difficult and less accurate. Therefore, denoising is not merely an aesthetic improvement but a critical enabling technology that allows for faster scanning, higher spatial resolutions, and more robust and accurate quantitative biomarker extraction.
Section 2: The Evolution of Denoising: From Classical Filters to the Dawn of AI
The quest to remove noise from images is as old as digital imaging itself. For decades, the field of medical image processing relied on a suite of "classical" algorithms developed from principles of signal processing and statistics. These methods laid the groundwork for modern techniques and established the fundamental trade-offs involved in denoising. However, their inherent limitations ultimately created a performance ceiling, paving the way for the paradigm shift brought about by artificial intelligence and deep learning.
2.1. An Overview of Traditional Methods: Spatial Filtering, Transform-Domain, and Patch-Based Approaches
Traditional denoising methods can be broadly classified into three families, each representing an increase in sophistication.
Spatial Filtering Methods: These are the most direct approaches, operating on the pixel values of the corrupted image within a local neighborhood.
Linear Filters: The simplest example is the Gaussian filter, which replaces each pixel with a weighted average of its neighbors, where the weights follow a Gaussian distribution. While effective at smoothing noise, it indiscriminately blurs all high-frequency content, including sharp edges and fine details.
Non-Linear Filters: To address the blurring issue, non-linear filters were developed. The median filter, for instance, replaces a pixel with the median value of its neighborhood, which is more robust to outlier noise. The bilateral filter is a more advanced edge-preserving technique that combines spatial-domain filtering with intensity-domain filtering. It averages neighboring pixels, but the weight of each neighbor depends not only on its spatial distance but also on its intensity difference from the central pixel. This means it averages within smooth regions but stops averaging across sharp edges.
Anisotropic diffusion is another technique that models the denoising process as a heat diffusion equation, encouraging smoothing parallel to edges but inhibiting it perpendicular to them.
Transform-Domain Methods: This class of methods operates on the principle that images can be represented more sparsely in a transformed domain. The process involves three steps: 1) applying a mathematical transform (e.g., Fourier, Wavelet) to the image, 2) manipulating the transform coefficients to suppress noise, and 3) applying the inverse transform to return to the image domain.
Wavelet Transform: This became a foundational technique due to its ability to represent both spatial and frequency information efficiently. Noise tends to be represented by small coefficients across many wavelet scales, while true image structure is represented by a few large coefficients. By applying a threshold to the wavelet coefficients (setting small ones to zero) and then inverting the transform, noise can be effectively removed.
Curvelets and Contourlets: These are more advanced transforms designed to better capture curved edges and contours in images, where wavelets might be less efficient.
Patch-Based (Non-Local) Methods: Representing the pinnacle of classical denoising, these algorithms are built on the principle of self-similarity—the observation that any given image patch often has many similar-looking counterparts elsewhere in the image.
Non-Local Means (NLM): Proposed by Buades et al., the NLM filter denoises a target patch by searching the entire image for other patches with a similar intensity profile. It then computes a weighted average of these similar patches to produce the final, denoised result for the target patch. NLM is widely regarded as an excellent technique for MRI denoising due to its effectiveness at preserving structural detail.
Block-Matching and 3D Filtering (BM3D): An influential and powerful extension of NLM, BM3D takes the concept of patch similarity a step further. First, it finds similar 2D patches and stacks them together to form a 3D group. Second, it applies a collaborative filtering step in a 3D transform domain (like a 3D wavelet or DCT) to this group, attenuating the noise. Finally, it inverts the transform and aggregates the denoised patches back into their original locations in the image. For many years, BM3D was considered the state-of-the-art in image denoising and remains a formidable baseline against which new methods are compared.
2.2. Inherent Limitations: The Trade-off Between Noise Reduction and Detail Preservation
Despite their ingenuity, classical methods suffer from several fundamental limitations that ultimately hindered their widespread clinical adoption and motivated the shift towards learning-based approaches.
The primary challenge is the persistent and difficult trade-off between noise removal and the preservation of diagnostically relevant details. Simpler filters inevitably cause blurring, smoothing away not just noise but also fine textures and sharp edges that may be indicative of pathology. While more advanced methods like NLM and BM3D are far better at edge preservation, they are not perfect and can still struggle with complex textures or very low SNR conditions.
A second major barrier is computational cost. The very mechanism that makes NLM and BM3D so effective—the exhaustive, non-local search for similar patches across the image—is also their Achilles' heel. This search is computationally intensive, making these algorithms very slow, especially for large 3D MRI volumes. The long processing times make them impractical for integration into the fast-paced workflows of a routine clinical radiology department, where reconstruction and post-processing must happen quickly. This created a critical bottleneck: the best-performing classical methods were too slow for clinical use.
Other limitations include the risk of introducing new artifacts during the filtering process, which is clinically unacceptable. Furthermore, many of these algorithms have several parameters that require careful manual tuning for optimal performance, and the best parameters can vary significantly depending on the image contrast, anatomy, and noise level, limiting their generalizability. Finally, while effective for simpler noise models like AWGN, classical methods often struggle with the complex, spatially-varying, and structured noise that arises from modern acceleration techniques like parallel imaging.
The evolution of these classical methods reveals a clear trajectory. The blurring caused by simple spatial filters led to the development of transform-domain methods and eventually to patch-based methods like NLM and BM3D, which were superior at preserving detail. However, the non-local search that gave NLM and BM3D their power also made them computationally prohibitive. This created a performance-versus-speed impasse that the field struggled to overcome. It was this specific bottleneck that deep learning was perfectly positioned to break. While training a deep neural network is computationally expensive, once trained, the inference step (the actual denoising of a new image) can be performed extremely rapidly on modern GPU hardware. Deep learning thus offered a path to potentially achieve or exceed the denoising performance of methods like BM3D but without the crippling computational cost at inference time, directly addressing the key limitation of the classical era.
Interestingly, the transition to AI did not mean abandoning the core principles of the best classical methods. The fundamental idea of exploiting non-local self-similarity, which was central to NLM and BM3D, has proven to be remarkably persistent. It has evolved and been integrated into the very fabric of modern AI architectures. Early hybrid models explicitly combined the two worlds, using a CNN to learn a better similarity metric to guide a traditional NLM filter. More profoundly, the self-attention mechanism at the heart of the most advanced Transformer models can be seen as a learned, dynamic, and data-driven implementation of the same non-local comparison concept. This demonstrates a sophisticated evolution of a core idea, not merely a replacement of an old technology with a new one.
Section 3: The Workhorse of Medical AI: Convolutional Neural Network Architectures
The advent of deep learning, and specifically Convolutional Neural Networks (CNNs), marked a revolutionary turning point in image analysis. By learning intricate feature hierarchies directly from data, CNNs overcame many of the limitations of classical, hand-engineered filters. They quickly established themselves as the workhorse of medical AI, delivering state-of-the-art performance in denoising and forming the architectural foundation upon which more advanced models are built.
3.1. Foundational Models: DnCNN, U-Net, and Autoencoders
Three primary CNN architectures have become foundational in the field of MRI denoising. Their principles are so effective that they are frequently used as components within more complex, modern networks.
The Denoising Convolutional Neural Network (DnCNN) was a seminal model that demonstrated the remarkable effectiveness of a relatively deep CNN for image denoising. It introduced two key concepts that became standards in the field. The first was residual learning. Instead of training the network to map a noisy image directly to a clean one (f(y)→x), which can be a complex mapping to learn, DnCNN learns to predict the residual noise component (f(y)→v). The final clean image is then easily obtained by subtracting the predicted noise from the noisy input (x=y−f(y)). This simplifies the optimization problem and improves performance. The second innovation was the use of batch normalization between convolutional layers, which stabilizes the training process and allows for deeper networks. The DnCNN architecture itself is a straightforward cascade of convolutional layers, making it a powerful and widely cited baseline.
Autoencoders (AEs) are unsupervised neural networks that learn efficient data codings. They consist of two parts: an encoder that compresses the input image into a low-dimensional latent representation, and a decoder that reconstructs the original image from this compressed representation. The compression acts as an "information bottleneck," forcing the network to learn the most salient and essential features of the image while discarding the less important information, which ideally includes the noise. Convolutional Autoencoders (CAEs), which use convolutional layers for the encoder and decoder, are a common and effective variant for image denoising tasks.
The U-Net architecture, though originally designed for biomedical image segmentation, has been adapted with tremendous success for image restoration and denoising. Like an autoencoder, it has a symmetric encoder-decoder structure that progressively downsamples the image to capture context and then upsamples it to reconstruct the output. Its defining feature is the use of skip connections, which concatenate feature maps from the encoder path directly to the corresponding layers in the decoder path. These connections provide a shortcut for high-resolution spatial information to bypass the bottleneck, allowing the decoder to reconstruct fine details and sharp edges with much greater fidelity. This ability to preserve detail makes the U-Net architecture exceptionally well-suited for denoising, where the primary goal is to remove noise without blurring critical anatomical structures.
3.2. Architectural Innovations and Training Paradigms
Building upon these foundational models, researchers have developed numerous innovations to specifically tailor CNNs to the unique challenges of MRI data.
A significant step was the move from 2D to 3D convolutions. MRI data is inherently volumetric, but early approaches often processed it as a series of independent 2D slices. This fails to exploit the strong anatomical correlation that exists between adjacent slices. By using 3D convolutional kernels, 3D CNNs can process the entire volume at once, learning features from the through-plane dimension and leading to more robust and accurate denoising, albeit at a higher computational cost.
Another critical innovation is the development of complex-valued networks. As discussed, standard CNNs operate on magnitude images, which discards the valuable phase information and forces the network to learn the complex, non-Gaussian Rician noise distribution. To overcome this, some models are designed to operate directly on the original complex-valued data from the scanner. These networks use complex-valued weights, convolutions, and activation functions. By working in the complex domain, they can leverage both magnitude and phase information and can be trained on the simpler, well-understood Gaussian noise model, which has been shown to lead to superior performance, particularly in handling the spatially varying noise introduced by parallel imaging.
The architectural evolution within CNNs reveals a consistent pattern of identifying and re-integrating information that was lost in simpler processing pipelines. The standard autoencoder loses high-frequency details in its bottleneck, so the U-Net adds skip connections to bring that information back. The 2D CNN loses volumetric context, so the 3D CNN is developed to process volumes holistically. The standard CNN operating on magnitude images loses phase information and must contend with Rician noise, so the complex-valued CNN is created to work with the original, complete data. This demonstrates a clear and logical progression toward building models that are more fully aware of the native structure of MRI data.
The dominant training paradigm for these models is supervised learning, which requires a large dataset of paired noisy input images and "clean" ground-truth target images. However, the "ground truth problem" is a fundamental challenge in MRI: truly noise-free images do not exist in practice. Researchers must therefore create surrogate ground truth. This is typically done in one of two ways: 1) acquiring images with a very high number of signal averages (high NEX), which is time-consuming but produces a high-SNR reference , or 2) taking high-quality images and computationally adding simulated Gaussian or Rician noise to create the noisy input pairs. This reliance on surrogate ground truth is a crucial point; it means that supervised models are often learning to reverse a specific, and potentially simplified, noise model. This can explain why they sometimes struggle to generalize to the complex and non-stationary noise patterns encountered in real-world clinical scans.
3.3. Performance and Limitations in Clinical Contexts
In terms of performance, CNN-based methods have proven to be a resounding success, consistently outperforming classical algorithms. Numerous studies show that CNNs yield significantly higher scores on quantitative metrics like Peak Signal-to-Noise Ratio (PSNR) and the Structural Similarity Index (SSIM) when compared to traditional filters like BM3D. For example, a study comparing various 3D denoising methods on both synthetic and real data found that a proposed multi-channel 3D CNN achieved a 3D PSNR of 38.16 on real data, substantially outperforming the 35.58 achieved by the classical state-of-the-art BM4D algorithm.
The most significant clinical impact of CNN-based denoising is its ability to enable faster scanning. By effectively removing noise, these algorithms can compensate for the SNR loss that occurs with accelerated acquisition techniques. This allows for the use of fewer signal averages (lower NEX) or higher parallel imaging acceleration factors, which can dramatically reduce scan times while maintaining or even improving image quality. This has profound implications for patient comfort, scanner throughput, and reducing motion artifacts.
Despite these successes, CNNs are not without limitations. Their performance is highly dependent on the training data; they are data-hungry, and a model's effectiveness is constrained by the size, diversity, and quality of the dataset it was trained on. This leads to the critical problem of generalizability and domain shift. A model trained exclusively on T1-weighted brain scans from a Siemens 3T scanner is unlikely to perform well on T2-weighted knee images from a GE 1.5T scanner. This lack of robustness across different scanners, anatomies, and imaging contrasts is a major hurdle for widespread clinical deployment. Furthermore, while CNNs are better at preserving detail than classical filters, they can still introduce subtle blurring in regions with very complex structures, such as the cerebellum, if the learned filters are not sufficiently adaptive. Finally, and most critically, a poorly trained or improperly generalized model runs the risk of generating new, subtle artifacts that could be mistaken for pathology, or conversely, removing true pathological features by misinterpreting them as noise.
Section 4: Generative Models for High-Fidelity Image Restoration
While standard CNNs learn a direct mapping from a noisy to a clean image, a more powerful class of models known as generative models learns the underlying distribution of the data itself. This allows them to generate new, highly realistic image content. Two types of generative models have dominated recent AI research and are being actively explored for MRI denoising: Generative Adversarial Networks (GANs) and Denoising Diffusion Probabilistic Models (Diffusion Models). These models can produce visually stunning results but come with a unique and critical set of risks that must be carefully considered in a clinical context.
4.1. The Adversarial Approach: Denoising with Generative Adversarial Networks (GANs)
GANs introduce a novel training paradigm based on competition. A GAN framework consists of two neural networks pitted against each other in a zero-sum game:
The Generator network takes a noisy image as input and attempts to produce a realistic, denoised version of it. Its goal is to create an output that is indistinguishable from a real, high-quality MR image.
The Discriminator network acts as an adversary. It is trained to differentiate between the "fake" images produced by the Generator and "real" high-quality ground-truth images.
The training process is an iterative loop. The Discriminator's feedback on which images look fake is used to update the Generator's parameters, teaching it to produce more convincing fakes. Simultaneously, the Generator's increasingly sophisticated fakes are used to train the Discriminator to become a better detector. This adversarial dynamic forces the Generator to learn not just the pixel-level content of the images but also the subtle textures, edges, and statistical properties that make them appear perceptually realistic to a discerning eye.
Architecturally, the Generator is often based on a U-Net or another encoder-decoder structure, while the Discriminator is typically a standard classification CNN. The loss function used to train GANs is a key component, usually combining a traditional pixel-wise reconstruction loss (like L1 or MSE) to ensure fidelity with an adversarial loss derived from the discriminator's output. This adversarial component penalizes the generator for producing images that the discriminator identifies as fake, pushing the results towards greater realism.
4.2. The Iterative Approach: Denoising with Diffusion Models
Diffusion models are a more recent and powerful class of generative models that have achieved state-of-the-art results in image synthesis. They operate based on a gradual, two-step process:
Forward Diffusion Process: This is a fixed process where, during training, a clean image is progressively destroyed by adding a small amount of Gaussian noise at each of a large number of discrete time steps. After hundreds or thousands of steps, the original image is transformed into pure, unstructured noise.
Reverse Denoising Process: The model, typically a U-Net-like architecture, is then trained to reverse this process. At each time step, it learns to predict and remove the small amount of noise that was added, thereby taking a single step back towards the clean image.
During inference, the denoising process starts with the noisy MRI image. The model estimates the noise level and then iteratively applies the learned reverse step multiple times, progressively refining the image and removing noise until a clean output is produced. This iterative refinement process allows diffusion models to generate images with exceptional detail and fidelity to the learned data distribution.
4.3. A Critical Concern: The Risk of Generating Clinically Misleading Synthetic Structures
The very power of generative models is also the source of their greatest risk in a medical context: the potential to hallucinate. Because these models learn the distribution of real images, they become exceptionally good at "filling in" details that are statistically plausible, even if those details are not actually supported by the input signal. This can manifest as the generation of synthetic structures or textures that were not present in the original, noisy data.
This is not a theoretical concern. A critical analysis of diffusion models applied to medical image denoising published at the 2024 MICCAI conference explicitly investigated this risk. The study came to two alarming conclusions. First, the iterative sampling process, which is a hallmark of diffusion models, can actually degrade image quality in terms of standard metrics, with PSNR dropping by up to 14% compared to a simple one-step denoising. Second, and more importantly, the study provided visual evidence that the stochastic nature of the sampling process can introduce alterations to the image content, generating synthetic structures that compromise the clinical validity of the denoised image. Another study on diffusion-based MRI reconstruction found that the models were vulnerable to small, worst-case perturbations that could cause them to generate fake tissue structures, which could catastrophically mislead a clinician.
GANs, while less prone to the iterative degradation seen in diffusion models, face their own challenges. Their training is notoriously unstable and can suffer from "mode collapse," where the generator learns to produce only a limited variety of outputs, regardless of the input.
This creates a fundamental tension in the development of AI for medical imaging. On one hand, there is a desire for perceptually high-quality images with sharp edges and realistic textures, which generative models excel at producing. On the other hand, there is an absolute requirement for diagnostic fidelity—the guarantee that the denoised image is a truthful representation of the acquired signal. A simple CNN trained with a pixel-wise loss function might produce a slightly blurrier but more faithful image, as it is heavily penalized for any deviation from the ground truth. A GAN or diffusion model might produce a sharper, more visually appealing image that achieves a high SSIM score but at the risk of being less truthful to the underlying data. The "best" algorithm is therefore not simply the one with the highest score on a given metric, but the one that strikes the most clinically appropriate and safe balance between these competing goals. The significant risks associated with purely data-driven generative models serve as a primary motivation for developing new paradigms, such as physics-informed AI, that can harness their power while constraining their behavior to ensure clinical safety and reliability.
Section 5: The New Vanguard: Transformer-Based Architectures
In recent years, a new class of neural network architecture, the Transformer, has emerged from the field of natural language processing and has begun to challenge the dominance of CNNs in computer vision. By employing a powerful self-attention mechanism, Transformers can model long-range dependencies within data more effectively than CNNs. When adapted for medical imaging, these models have demonstrated state-of-the-art performance, particularly in the most challenging, low-SNR scenarios, positioning them as the new vanguard in the quest for high-fidelity MRI denoising.
5.1. Adapting Attention Mechanisms for Medical Imaging (e.g., SwinIR, Imaging Transformer)
The core innovation of the Transformer is the self-attention mechanism. For any given patch (or "token") in an image, self-attention dynamically computes a set of "attention scores" that weigh the importance of all other patches in the image for interpreting the current one. This allows the model to build a rich, context-aware representation by explicitly modeling the relationships between distant parts of the image, overcoming the inherently local receptive field of a CNN's convolutional kernel.
Adapting this powerful mechanism for high-resolution images has led to several key architectural developments:
Swin Transformer: A standard Vision Transformer (ViT) processes an image by breaking it into a sequence of patches and applying global self-attention, which is computationally expensive. The Swin (Shifted Window) Transformer makes this process more efficient by first computing self-attention only within local, non-overlapping windows. It then achieves cross-window communication by shifting the window grid in subsequent layers. This hierarchical approach provides the benefits of global context modeling while maintaining linear computational complexity with respect to image size, making it practical for vision tasks.
SwinIR: This model is a strong baseline for general image restoration tasks, built upon the Swin Transformer. Its architecture consists of three main parts: a shallow feature extraction module (typically using CNNs), a deep feature extraction module composed of several Residual Swin Transformer Blocks (RSTBs), and a final high-quality image reconstruction module. SwinIR has demonstrated state-of-the-art performance on standard denoising benchmarks.
Imaging Transformer (IT): This is a highly specialized and powerful architecture developed by Microsoft Research specifically for MRI denoising. It represents a sophisticated synthesis of the best ideas from both the CNN and Transformer worlds. It uses a High-Resolution Network (HRNet) as its backbone to maintain high-resolution feature maps throughout the network—a concept proven effective in CNNs. Embedded within this backbone are novel IT blocks that decompose the attention mechanism into three specialized modules: spatial local attention, spatial global attention, and frame (or temporal) attention. This design allows it to process 5D tensors (Batch, Channel, Frame, Height, Width), making it exceptionally versatile for handling 2D, 3D, and dynamic (2D+T) MRI data with a single unified architecture.
5.2. Scalability and Performance in Extremely Low-SNR Scenarios
The performance of Transformer-based models, particularly in challenging conditions, has been remarkable. Studies consistently show that architectures like SwinIR and IT significantly outperform strong CNN and even other Transformer baselines.
The most compelling evidence of their power comes from their performance in extremely low-SNR regimes. The Microsoft Imaging Transformer (IT) was tested on cine MRI data with input SNR levels as low as 0.2, a level at which the raw images are completely obscured by noise and clinically uninterpretable. The model was able to recover high-quality images with clear anatomical details. Crucially, this was not just a cosmetic improvement; a qualitative review by two senior cardiologists confirmed that the denoised images provided the same clinical interpretation as the high-SNR ground-truth images. Furthermore, quantitative measurements like the left ventricular Ejection Fraction (EF) derived from the denoised images were accurate when compared to ground-truth values.
This capability has profound implications for the future of MRI. The demonstrated ability of Transformers to produce clinically valid results from inputs with SNR << 1 could fundamentally alter the landscape of MRI hardware. It opens the door for low-field MRI (e.g., 0.55T systems), which is inherently cheaper, smaller, and more accessible than high-field systems, to become a viable alternative for a wide range of clinical applications. By computationally compensating for the intrinsic low SNR of these systems, advanced AI denoising could democratize access to MRI technology, particularly in under-resourced or point-of-care settings.
The IT architecture also demonstrated excellent scalability. Performance, as measured by SSIM and PSNR, consistently improved as the model size was increased from 27 million to 218 million parameters, indicating a high capacity for learning complex noise patterns from massive datasets. Subsequent work on a related "imformer" model, which used a novel "SNR unit" training scheme, showed strong generalization across different scanner field strengths, imaging contrasts, and anatomical regions, addressing a key challenge of clinical translation.
5.3. Comparative Edge over CNN-based Approaches
Transformers hold several key advantages over purely CNN-based approaches for image denoising:
Global Context Modeling: As mentioned, their ability to model long-range dependencies allows them to understand the global structure of the anatomy and capture non-local noise correlations that are beyond the reach of a CNN's fixed-size kernel.
Content-Based, Dynamic Operations: The self-attention weights are calculated dynamically based on the image content itself. This can be interpreted as a far more powerful and flexible version of a spatially varying convolution, where the "filter" adapts to the local structures in the image.
Parameter Efficiency: Models like SwinIR have been shown to achieve superior performance while using significantly fewer parameters than competing CNN models, suggesting a more efficient representation of the denoising task.
However, the trend in state-of-the-art research is not necessarily a wholesale replacement of CNNs with Transformers, but rather the development of powerful hybrid models that leverage the strengths of both. Models like SwinMR and RepCHAT use CNN layers for efficient local feature extraction at the shallow and deep ends of the network, while using a Transformer-based backbone to handle the complex, global feature integration. This suggests that the inductive bias of CNNs for local patterns and the global context modeling of Transformers are highly complementary, and their combination represents the current frontier of architectural design.
Section 6: Emerging Paradigms for Robust and Data-Efficient Denoising
While architectural innovations in CNNs and Transformers have pushed the boundaries of performance, two parallel and equally important lines of research have focused on fundamentally changing how models are trained. These emerging paradigms—self-supervised learning and physics-informed learning—directly address the most critical bottlenecks of standard supervised AI: the dependence on massive, perfectly curated datasets and the lack of inherent robustness and trust.
6.1. Self-Supervised Learning: Breaking the Dependence on Clean Ground-Truth Data
The single greatest practical challenge in developing AI for medical imaging is the "ground truth problem." Standard supervised learning requires vast datasets of paired noisy input images and perfectly clean target images. As has been established, acquiring truly noise-free MRI data is physically impossible, making the creation of such datasets impractical and forcing researchers to rely on imperfect surrogates.
Self-supervised learning (SSL) is a paradigm shift that elegantly sidesteps this issue by training models using only the noisy data itself. These methods work by exploiting the statistical properties of noise and the inherent redundancy within the image data. Several key techniques have been developed:
Noise2Noise (N2N): This approach requires two independent noisy acquisitions of the same scene. The network is trained to map one noisy image to the other. Because the underlying anatomical signal is the same in both images but the random noise is uncorrelated, the optimal strategy for the network to minimize the error is to learn the true, underlying clean signal. The main challenge for applying N2N to MRI is that patient motion between the two required scans can be difficult to avoid, violating the assumption of a static underlying scene.
Blind-Spot Networks: This is a more practical and widely used family of SSL methods that only requires a single noisy image. The core idea is to train the network to predict a given pixel's value based only on its surrounding neighbors, with the central target pixel being artificially "masked" or excluded from the network's receptive field for that prediction. Since the noise at a given pixel is generally statistically independent of the noise at its neighbors, the network cannot simply learn an identity mapping. To make an accurate prediction, it is forced to learn the underlying anatomical structure from the context provided by the neighboring pixels. Prominent examples of this approach include Noise2Void (N2V) and Self2Self (S2S).
Stein's Unbiased Risk Estimator (SURE): This is a statistical framework that allows a network to be trained with a loss function that provides an unbiased estimate of the true mean squared error to a clean ground truth, even without ever seeing that ground truth. It effectively allows for supervised-style training without supervised data.
The performance of these methods has been impressive. A recent study on a multidimensional self-supervised technique (MD-S2S) showed that it drastically improved denoising performance over classical methods like BM3D and other SSL approaches like Patch2self. Critically, it also led to pronounced improvements in the accuracy of downstream quantitative parameter maps derived from the denoised images. SSL represents a transformative approach that makes robust, data-efficient deep learning feasible for a much wider range of clinical applications where paired data is scarce.
6.2. Physics-Informed Neural Networks (PINNs): Integrating Physical Priors for Enhanced Robustness
A major criticism of purely data-driven AI models is that they can operate as "black boxes," potentially learning spurious correlations from the training data or producing outputs that, while visually plausible, violate the known laws of physics. Physics-Informed Neural Networks (PINNs) address this by explicitly integrating domain knowledge of the underlying physical process into the learning framework.
In the context of MRI denoising, this is typically achieved by adding a physics-based loss term to the network's objective function. This term penalizes the network if its output is inconsistent with a known physical model of MR signal behavior. For example:
In Diffusion-Weighted Imaging (DWI), the signal intensity is known to decay exponentially with increasing b-value. A PINN designed for DWI denoising can incorporate a loss term that ensures the denoised signal intensities across multiple b-values adhere to this physical model. This not only regularizes the network to prevent hallucinations but also helps preserve the quantitative accuracy of derived parameters like the Apparent Diffusion Coefficient (ADC).
In MRI reconstruction and artifact correction, PINNs can be informed by the physics of image formation itself. A data consistency loss term can be used to ensure that the k-space representation of the denoised image remains consistent with the originally acquired (albeit noisy and undersampled) k-space data.
The results of this approach are highly promising. A 2025 study on a PINN for high b-value DWI denoising, named PIND, reported outstanding performance. It improved PSNR from 31.25 dB to 36.28 dB and SSIM from 0.77 to 0.92. Most importantly, it did so while maintaining 98% accuracy of the quantitative ADC value and enabling a potential 83% reduction in scan time. This demonstrates that PINNs can achieve excellent noise reduction without sacrificing the quantitative integrity of the data, a crucial requirement for clinical translation.
The rise of both self-supervised learning and physics-informed learning can be seen as a form of convergent evolution. Both paradigms are fundamentally aimed at solving the same core challenge: the ill-posed nature of image restoration when perfect ground truth is unavailable. They achieve this by introducing powerful forms of regularization to constrain the vast solution space. Self-supervision adds a statistical constraint, enforcing consistency within the noisy data itself. PINNs add a physical constraint, enforcing consistency with the known laws of the imaging modality. They represent two different but complementary paths toward the same goal: creating smarter, more robust, and more trustworthy AI models that are less dependent on impossibly large and perfect datasets. This trend is a direct response to the clinical community's valid skepticism of "black box" AI and is critical for bridging the gap between laboratory research and real-world clinical adoption.
6.3. Hybrid Models: Combining the Strengths of Classical and AI-based Methods
While the focus of research has shifted heavily towards end-to-end deep learning, a pragmatic and highly effective approach involves creating hybrid models that combine the strengths of AI with the well-understood principles of classical algorithms. Rather than treating classical methods as obsolete, this approach views them as powerful priors that can be enhanced by deep learning.
One of the most successful early hybrid strategies was the use of an AI-guided classical filter. In this two-stage approach, a CNN is first used to produce a preliminary, pre-filtered image. This output, while imperfect, is a much better estimate of the clean image than the original noisy input. This pre-filtered image is then used as a "guide image" within a traditional NLM or BM3D filter. By providing a better reference for the patch similarity search, the CNN dramatically improves the performance of the classical filter, leading to results superior to what either method could achieve alone. This method also helps to mitigate blocking artifacts that can sometimes be produced by patch-based CNNs.
Another hybrid approach involves combining AI with transform-domain methods. For instance, a method for CT denoising was developed that first applies a non-subsampled shearlet transform, and then uses a DnCNN as a post-processing step to clean up any residual noise that remains after the transform-based filtering. These hybrid models represent a powerful reminder that decades of research in classical image processing have produced valuable tools and concepts that can be intelligently integrated with, rather than simply replaced by, modern deep learning techniques.
Section 7: A Comparative Performance Analysis
Determining the "best" AI denoising method requires a multi-faceted evaluation that goes beyond a single performance metric. It involves a critical assessment of quantitative benchmarks, qualitative clinical utility, modality-specific performance, and practical considerations like computational cost. While the research landscape is fragmented, making a definitive, all-encompassing comparison challenging, a clear hierarchy of performance and a set of key trade-offs emerge from the available evidence.
7.1. Quantitative Benchmarking: Evaluating PSNR, SSIM, and Other Key Metrics
The most common objective metrics used to evaluate denoising algorithms are the Peak Signal-to-Noise Ratio (PSNR) and the Structural Similarity Index (SSIM). PSNR is a measure of pixel-wise reconstruction error based on the Mean Squared Error (MSE), while SSIM is designed to better align with human perception of structural information, luminance, and contrast.
Based on these metrics, a clear performance hierarchy can be established from the literature:
Deep Learning > Classical Methods: Across numerous studies, deep learning models consistently and significantly outperform even the most advanced classical methods like BM3D and its volumetric variant, BM4D. For example, in a direct comparison of 3D denoising methods, a proposed multi-channel 3D CNN achieved a 3D PSNR of 38.16 and 3D SSIM of 0.9924 on real MRI data, whereas the state-of-the-art classical method BM4D achieved only 35.58 and 0.9882, respectively.
Advanced DL Architectures > Simple Baselines: Within the deep learning ecosystem, more advanced architectures generally outperform simpler ones. Models that incorporate mechanisms for capturing long-range information, such as Transformers (e.g., SwinIR) or CNNs with U-Net structures and non-local modules, show substantial improvement over pure, feed-forward CNN structures like the original DnCNN. Transformer-based models like the Imaging Transformer have also been shown to outperform other CNN and Transformer baselines.
The following table, synthesized from a comparative study on 3D MRI denoising, provides concrete evidence of this hierarchy on real data. The "3D-Proposed" model is a multi-channel 3D CNN.
Table 1: Quantitative Performance Benchmark on Real 3D MRI Data
| Metric | Input | BM4D (Classical) | 3D-DnCNN | 3D-EnsembleNet | 3D-Proposed |
| 3D PSNR | 34.77±2.12 | 35.58±1.88 | 37.92±2.15 | 37.98±2.00 | 38.16±2.45 |
| 3D SSIM | 0.9852±0.0054 | 0.9882±0.0038 | 0.9918±0.0030 | 0.9921±0.0028 | 0.9924±0.0030 |
However, it is crucial to recognize the limitations of these metrics. PSNR and SSIM do not always correlate with diagnostic utility. A high PSNR can be achieved by an algorithm that excessively smooths the image, while a high SSIM can be produced by a generative model that hallucinates plausible but fake details. This "benchmark illusion" is a systemic challenge in the field; with no single, universally accepted benchmark dataset or evaluation protocol, comparing results across different papers can be misleading. A model that is state-of-the-art in one study may be outperformed when tested on a different anatomy or against a different set of competing models. This underscores the need for both qualitative assessment and the development of more clinically relevant evaluation metrics.
7.2. Modality-Specific Performance: T1-weighted, T2-weighted, and Diffusion-Weighted Imaging (DWI)
The optimal denoising strategy can vary significantly depending on the specific MRI sequence, as each presents unique challenges related to its contrast mechanism and noise characteristics.
T1- and T2-weighted Imaging: For standard anatomical imaging, deep learning reconstruction (DLR) has been shown to be broadly effective. Studies on pediatric body MRI using T1- and T2-weighted sequences found that DLR significantly improved both SNR and CNR, leading to higher overall image quality scores from radiologists compared to conventional reconstruction.
Quantitative T1-mapping: This advanced technique provides quantitative biomarkers of tissue health but is sensitive to noise. A study evaluating a super-resolution DLR (SR-DLR) for myocardial T1 mapping found that it did not alter the mean T1 value (preserving quantitative accuracy) but significantly reduced the standard deviation of the measurements. This indicates that the DLR method improved the precision and reliability of the T1 maps without introducing bias.
Diffusion-Weighted Imaging (DWI): DWI is arguably the most challenging and important modality for denoising. The signal in DWI is inherently low, especially at the high b-values needed to probe tissue microstructure, making it highly susceptible to noise that can overwhelm the signal and bias quantitative measurements. Consequently, many specialized AI methods have been developed for DWI. A simple 1D-CNN, applied voxel-wise along the diffusion-encoding dimension, was shown to be an effective method for high b-value DWI, overcoming limitations of other methods like Marcenko-Pastur PCA (MP-PCA). Self-supervised methods like Noise2Noise have also been successfully applied, circumventing the need for clean ground-truth data. Most promisingly, physics-informed models like PIND, which leverage the known physics of diffusion, have demonstrated excellent noise reduction while preserving the accuracy of quantitative ADC maps with high fidelity.
This analysis highlights that while general-purpose denoisers can be effective, the most challenging and quantitatively sensitive modalities like DWI and T1-mapping often benefit from specialized AI solutions designed to handle their unique signal properties and preserve their quantitative integrity.
7.3. Qualitative Evaluation: The Role of Radiologist Assessment in Determining Clinical Viability
While quantitative metrics provide a measure of mathematical fidelity, the ultimate arbiter of an algorithm's success is its clinical utility, which can only be determined through qualitative assessment by expert human observers. A denoised image is only useful if it improves, or at a minimum does not hinder, a radiologist's ability to make an accurate diagnosis.
Many high-quality studies incorporate reader studies as a critical component of their validation process. For instance:
An AI method for accelerated brain MRI was evaluated by five board-certified radiologists, who confirmed that the AI-enhanced images preserved the visibility of key pathological features.
The Imaging Transformer model was validated by two senior cardiologists who agreed that its output provided the same clinical interpretation as the ground-truth images, even from extremely noisy inputs.
A reader study involving four radiologists confirmed that the PIND model for DWI showed promising performance on overall image quality, artifact suppression, and lesion conspicuity.
Radiologist assessment is also crucial for identifying the failure modes of AI. An expert radiologist was able to identify that a network trained with an MSE cost function resulted in unacceptable oversmoothing of images, leading the researchers to switch to a more effective MAE loss function. This underscores the fact that quantitative metrics alone are insufficient for model development and validation. Clinical translation of any denoising algorithm absolutely requires rigorous, in-the-loop validation by radiologists to ensure the resulting images are not just visually appealing, but are diagnostically safe and effective.
7.4. Computational Cost and Inference Time: Practical Considerations for Deployment
For an AI algorithm to be integrated into a clinical workflow, it must be computationally efficient. A key advantage of deep learning over advanced classical methods like BM3D is the separation of training and inference. While training a deep network can take hours or days, the inference process—applying the trained model to denoise a new image—is typically very fast, often taking seconds or less on a GPU.
However, not all AI models are created equal in terms of computational cost. There is a clear trade-off between model complexity and efficiency. A comparative study of different DL models found that a simpler noise-to-clean (N2C) network was the most computationally efficient, while a more complex CycleGAN was the least efficient. Within 3D CNNs, a multi-channel architecture was shown to have fewer trainable parameters and lower computational requirements (FLOPs) than a standard 3D-DnCNN while achieving better performance. Diffusion models are a notable outlier; their iterative sampling process makes their inference time significantly longer than that of single-pass models like CNNs or Transformers, which is a major practical barrier to their clinical deployment. Therefore, when selecting a model, one must consider not only its accuracy but also its inference speed and computational footprint to ensure it can be practically deployed in a time-sensitive clinical environment.
The following table provides a high-level synthesis of the key trade-offs between the major AI architectural classes discussed.
Table 2: Comprehensive Comparison of State-of-the-Art AI Denoising Architectures
| Architecture Class | Example Model(s) | Core Principle | Training Paradigm | Key Strengths | Notable Weaknesses |
| CNN | DnCNN, U-Net, ResNet | Convolutional filters, Residual learning, Skip connections | Supervised, Self-Supervised | Fast inference, strong baseline, mature technology | Limited receptive field, struggles with global context |
| GAN | cGAN, WGAN | Adversarial training (Generator vs. Discriminator) | Supervised, Unsupervised | Excellent perceptual quality, sharp images | Training instability, risk of hallucinating details |
| Transformer | SwinIR, Imaging Transformer | Self-attention mechanism | Supervised | Excellent global context modeling, SOTA performance in low-SNR | Computationally intensive (mitigated by Swin), newer architecture |
| Diffusion Model | DDPM, Di-Fusion | Iterative denoising (reverse diffusion process) | Supervised, Self-Supervised | SOTA generative quality, highly realistic textures | Very slow inference, high risk of hallucination, can degrade metrics |
| PINN | PIND | Physics-informed loss function | Supervised, Self-Supervised | High robustness, preserves quantitative accuracy, more trustworthy | Requires a known physical model, application-specific |
Section 8: From Laboratory to Clinic: Challenges and Future Horizons
Despite the remarkable progress in developing powerful AI denoising algorithms, the path from a successful research paper to a widely adopted clinical tool is fraught with significant challenges. Overcoming these hurdles related to robustness, trust, and practical implementation will define the future of AI in medical imaging. The successful translation of these technologies requires a concerted effort to move beyond optimizing performance on curated datasets and toward building reliable, generalizable, and transparent systems.
8.1. The "Domain Shift" Problem: Generalizability and Robustness
The most significant technical barrier to the widespread clinical adoption of AI is the "domain shift" or "dataset shift" problem. An AI model, particularly one trained with supervised learning, tends to perform exceptionally well on data that is similar to its training data ("in-domain") but can fail unpredictably when deployed on data from a different source ("out-of-domain"). This mismatch can arise from variations in scanner manufacturer (e.g., Siemens vs. GE vs. Philips), field strength (1.5T vs. 3T), acquisition protocols, patient populations, or even software versions. An AI model that produces state-of-the-art results on a public dataset from one institution may not be robust or reliable when used in a different hospital, a phenomenon that undermines its clinical utility.
This problem is exacerbated by biases in training data. Models trained on small or insufficiently diverse datasets will almost certainly fail to capture the vast heterogeneity of real-world clinical cases and are prone to learning spurious correlations specific to the training set. The fragmentation of the research landscape, with different studies using different datasets and evaluation methods, makes it difficult to truly assess the generalizability of new models.
Addressing this challenge is a primary focus of current research. Key strategies include:
Training on large, diverse, multi-site datasets to expose the model to a wider range of domains.
Developing vendor-agnostic solutions that can operate as post-processing tools on images from any scanner, often by avoiding reliance on proprietary raw k-space data.
Advancing unsupervised and self-supervised learning methods, which can be more readily adapted to new data domains since they do not rely on a fixed set of ground-truth labels from a specific source domain.
8.2. The "Black Box" Problem: Interpretability and Trust
For clinicians to confidently integrate AI into their diagnostic workflow, they must be able to trust its outputs. A major obstacle to this trust is the "black box" nature of many deep learning models. It can be exceedingly difficult to understand why a complex network made a particular decision—for example, why it smoothed a certain region or preserved a specific texture. This lack of transparency is a significant barrier to clinical adoption.
The risks are substantial. An uninterpretable model could be systematically erasing subtle but important pathological features, or generating plausible-looking artifacts, for reasons that are not apparent to the user. Without understanding the model's failure modes, it cannot be safely deployed.
This has spurred the field of Explainable AI (XAI), which aims to develop techniques for making model behavior more transparent and human-understandable. In the context of denoising, this could involve generating "saliency maps" that highlight which parts of the input image most influenced the denoised output. An even more powerful solution lies in the paradigm of Physics-Informed Neural Networks (PINNs). By explicitly constraining the model's behavior with the known laws of MR physics, PINNs are inherently more interpretable and trustworthy. A clinician can have greater confidence in a model that is guaranteed to produce outputs consistent with physical principles they already understand and trust.
8.3. The Role of Open-Source Frameworks and Vendor-Agnostic Solutions
The rapid pace of innovation in AI-based denoising has been fueled by a strong culture of open science. The availability of open-source software and large-scale public datasets is critical for ensuring research is reproducible, allowing for fair benchmarking, and enabling the community to build upon prior work.
Several key resources have been instrumental in this progress. Frameworks like MONAI, a PyTorch-based library developed specifically for medical imaging, provide a standardized set of tools for data handling, training, and evaluation. Data-handling libraries like TorchIO further streamline the complex preprocessing pipelines required for 3D medical images. The release of large, public datasets, most notably the fastMRI dataset of raw k-space data from NYU Langone Health, has provided a common ground for developing and testing reconstruction and denoising algorithms. Furthermore, many researchers now release the code for their models on platforms like GitHub, allowing others to validate their results and adapt their architectures.
While open-source tools accelerate research, clinical deployment often involves commercial solutions integrated directly by scanner vendors (e.g., Philips SmartSpeed AI, Canon's dDLR). These systems are powerful but are often proprietary "black boxes." A parallel and important trend is the development of vendor-agnostic software that can be applied as a post-processing step to DICOM images from any scanner, which is crucial for ensuring that advanced AI tools are accessible to institutions with multi-vendor fleets.
The following table provides a list of key open-source resources for researchers and developers interested in MRI denoising.
Table 3: Key Open-Source Implementations and Datasets for MRI Denoising
| Resource Name | Type | Link/Reference | Description/Relevance |
| MONAI | Framework | github.com/Project-MONAI/MONAI | A PyTorch-based, open-source framework for deep learning in healthcare imaging. Provides standardized tools for preprocessing, training, and analysis. |
| DIPY | Library | github.com/dipy/dipy | A Python library for the analysis of 3D/4D+ medical imaging, with a focus on diffusion MRI. Includes methods for denoising and processing. |
| SwinIR | Model Impl. | github.com/JingyunLiang/SwinIR | Official PyTorch implementation of the Swin Transformer for Image Restoration, a state-of-the-art model for denoising and other tasks. |
| DnCNN | Model Impl. | github.com/cszn/DnCNN | Official implementation (MATLAB/PyTorch) of the foundational Denoising Convolutional Neural Network. |
| fastMRI Dataset | Dataset | fastmri.med.nyu.edu | A large-scale dataset of raw k-space data for brain and knee MRI, essential for training and validating reconstruction and denoising models. |
| TorchIO | Library | github.com/fepegar/torchio | A Python library for efficient loading, preprocessing, augmentation, and patch-based sampling of 3D medical images in PyTorch. |
8.4. Future Research Trajectories and Unresolved Questions
The field of AI-based MRI denoising is dynamic and rapidly evolving. While significant progress has been made, several key challenges remain, defining the most promising directions for future research.
A powerful trend is the development of more sophisticated hybrid systems. The future likely lies not in a single "pure" architecture, but in intelligent combinations that leverage the local feature extraction of CNNs, the global context modeling of Transformers, and the robust constraints of physics-informed learning.
A critical and still largely unsolved problem is uncertainty quantification. A truly clinical-grade AI should not only produce a denoised image but also provide a measure of its own confidence. It should be able to generate an "uncertainty map" that highlights regions of the image where its reconstruction is less reliable, flagging these areas for heightened scrutiny by the radiologist.
Another promising avenue is multimodal learning. MRI scans often involve acquiring multiple contrasts (e.g., T1w, T2w, FLAIR, DWI). Future models could be designed to leverage the complementary information across these different contrasts to achieve more robust denoising than by processing each one in isolation.
Finally, the scope of AI is expanding from pure denoising to simultaneous artifact correction. The next generation of models will aim to create unified frameworks that can correct for noise, motion artifacts, Gibbs ringing, and other sources of image degradation all at once.
Ultimately, the trajectory of the field suggests a move away from a purely model-centric view towards a more data-centric one. While better architectures will continue to emerge, the most significant future breakthroughs may come from developing better strategies for acquiring, curating, and learning from data. The success of self-supervised learning, which cleverly works around the "no ground truth" problem, is a testament to this. Future work on federated learning (to train on diverse, decentralized data while preserving privacy), the creation of larger and more comprehensive open benchmarks, and new ways of learning from limited or imperfect data will be just as important, if not more so, than designing the next novel neural network layer.
Section 9: Conclusion and Recommendations
The application of artificial intelligence to magnetic resonance image denoising has transitioned from a promising research concept to a powerful clinical reality. The evolution from classical filters to sophisticated deep learning architectures has fundamentally shifted the trade-off between image quality and acquisition speed, opening new possibilities for faster, higher-resolution, and more accessible MRI. However, the landscape of AI denoising is complex and nuanced, with no single algorithm reigning supreme across all applications and evaluation criteria. The determination of the "best" AI denoiser is highly context-dependent.
9.1. Synthesizing the State-of-the-Art: Which AI Denoising Method is "Best"?
Answering the query of which AI method is "best" requires deconstructing the term into a set of distinct, and sometimes competing, objectives:
For Raw Performance and Pushing SNR Boundaries: The current state-of-the-art for sheer denoising power, especially in extremely low-SNR regimes, belongs to Transformer-based architectures. Models like the specialized Imaging Transformer have demonstrated an unprecedented ability to recover clinically valid information from images with SNR levels below 1.0, a feat that was previously considered impossible. Their strength lies in effectively modeling global context, making them the vanguard for applications where maximizing image quality from the noisiest inputs is the primary goal.
For Robustness and Quantitative Accuracy: The most promising emerging paradigm is Physics-Informed Neural Networks (PINNs). By integrating the physical laws of MR signal formation directly into the learning process, PINNs offer a powerful mechanism to ensure outputs are not only visually clean but also quantitatively accurate and physically plausible. For quantitative modalities like DWI or T1-mapping, where preserving biomarker accuracy is paramount, PINNs represent the most direct path to building trustworthy and reliable models.
For Data Efficiency and Practical Deployment: The most significant bottleneck to developing and deploying supervised AI is the need for vast quantities of clean ground-truth data, which is unavailable for MRI. Self-supervised learning directly solves this problem by enabling models to be trained using only noisy clinical data. For researchers and institutions looking to develop bespoke models on their own data without the burden of creating paired datasets, self-supervised methods are the most practical and scalable path forward.
For a Balance of Performance and Maturity: Well-designed 3D Convolutional Neural Networks, particularly those based on the U-Net architecture, remain a powerful, mature, and widely used standard. They offer a robust balance of performance and computational efficiency and form the backbone of many successful research and commercial systems. While perhaps no longer the absolute state-of-the-art in raw performance, they are a proven and reliable workhorse.
For Perceptual Quality (with a Caveat): Generative models like GANs and Diffusion Models are unmatched in their ability to produce images with high perceptual quality, realistic textures, and sharp edges. However, this capability comes with a significant and unresolved risk of "hallucinating" clinically misleading details. Until their reliability and fidelity can be rigorously guaranteed, they must be used with extreme caution in any diagnostic setting.
9.2. Recommendations for Researchers and Practitioners
Based on this comprehensive analysis, the following recommendations are offered to guide future work and clinical adoption:
For Researchers:
Focus on Clinically-Relevant Challenges: Shift focus from incremental PSNR gains on standard benchmarks towards solving the key challenges of generalizability, interpretability, and uncertainty quantification. The field needs models that are robust to domain shift and can communicate their own confidence to the end-user.
Embrace Hybrid and Constrained Models: The most promising future directions lie in the intelligent combination of architectures. Explore hybrid models that merge the strengths of CNNs, Transformers, and physics-informed principles. Using physical priors to constrain powerful generative models may be a key to unlocking their potential safely.
Promote Open and Standardized Benchmarking: To move beyond the "benchmark illusion," the community should work towards creating large-scale, multi-site, multi-vendor public datasets and standardized evaluation protocols. This is essential for enabling fair, reproducible comparisons and for truly measuring progress in generalizability.
For Clinical Practitioners (Radiologists, Medical Physicists):
Evaluate Beyond the Metrics: When assessing a commercial or research AI tool, look beyond the headline PSNR and SSIM scores. Insist on validation using a diverse set of local data that reflects your patient population and scanner protocols.
Prioritize Qualitative and Quantitative Validation: The gold standard for validation is qualitative assessment by multiple expert radiologists to confirm that diagnostic quality is maintained or improved and that no artifacts are introduced. For quantitative imaging sequences (DWI, T1-mapping, etc.), it is imperative to verify that the AI tool preserves the accuracy and precision of the derived biomarkers.
Maintain a "Trust but Verify" Approach: Embrace the potential of AI to improve image quality and workflow efficiency, but maintain a healthy clinical skepticism. Be aware of the potential failure modes, particularly the risk of hallucinated or erased pathology, and collaborate closely with developers and physicists to ensure that AI tools are rigorously tested and meet the specific needs and safety standards of your clinical practice.
References
Noise and artifacts in MR images (Chapter 11) - Introduction to Functional Magnetic Resonance Imaging - Cambridge University Press, accessed July 17, 2025, https://www.cambridge.org/core/books/introduction-to-functional-magnetic-resonance-imaging/noise-and-artifacts-in-mr-images/0D06ED6766D1CF57386CCE556B99AEBB
Noise and filtration in magnetic resonance imaging - PMC - PubMed Central, accessed July 17, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC2169200/
The Rician Distribution of Noisy MRI Data - PMC, accessed July 17, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC2254141/
Image Denoising Using Non-Local Means (NLM) Approach in ..., accessed July 17, 2025, https://www.mdpi.com/2076-3417/10/20/7028
MR Acoustics - Questions and Answers in MRI, accessed July 17, 2025, https://www.mriquestions.com/whats-that-noise.html
Why are MRI scans so loud? - Radiating Hope - Cincinnati Children's Blog, accessed July 17, 2025, https://radiologyblog.cincinnatichildrens.org/whats-with-all-the-noise/
ocimakamboj/DnCNN: Image Denoising with Residual Learning - GitHub, accessed July 17, 2025, https://github.com/ocimakamboj/DnCNN
MRI denoising with a non-blind deep complex-valued convolutional neural network, accessed July 17, 2025, https://pubmed.ncbi.nlm.nih.gov/39523816/
Evaluation of MRI Denoising Methods Using Unsupervised Learning - Frontiers, accessed July 17, 2025, https://www.frontiersin.org/journals/artificial-intelligence/articles/10.3389/frai.2021.642731/full
How denoising algorithms can improve MRI image quality - News-Medical.net, accessed July 17, 2025, https://www.news-medical.net/whitepaper/20250117/How-denoising-algorithms-can-improve-MRI-image-quality.aspx
Convolutional Neural Network for MR Image Noise Removal, accessed July 17, 2025, https://www.csie.ntu.edu.tw/~fuh/personal/ConvolutionalNeuralNetworkforMRImageNoiseRemoval.pdf
Convolutional neural network denoising technique on MRI examination using parallel imaging grappa (Generalized autocalibrating p, accessed July 17, 2025, https://www.radiologypaper.com/article/view/386/7-2-8
Denoising diffusion weighted imaging data using convolutional neural networks | PLOS One, accessed July 17, 2025, https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0274396
Medical Image Denoising Techniques: A Review - ResearchGate, accessed July 17, 2025, https://www.researchgate.net/publication/357876362_Medical_Image_Denoising_Techniques_A_Review
94 - Denoising MRI images (also CT & microscopy images) - YouTube, accessed July 17, 2025, https://www.youtube.com/watch?v=ur6pi3L98kk
Evaluation of MRI Denoising Methods Using Unsupervised Learning - PMC, accessed July 17, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC8212039/
(PDF) From Classical to Deep Learning: A Systematic Review of Image Denoising Techniques - ResearchGate, accessed July 17, 2025, https://www.researchgate.net/publication/382408601_From_Classical_to_Deep_Learning_A_Systematic_Review_of_Image_Denoising_Techniques
Overview of Research on Digital Image Denoising Methods - PMC - PubMed Central, accessed July 17, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC12031399/
What is the best denoising algorithm for Brain mri images? - ResearchGate, accessed July 17, 2025, https://www.researchgate.net/post/what_is_the_best_denoising_algorithm_for_Brain_mri_images
Validation of a Denoising Method Using Deep Learning–Based Reconstruction to Quantify Multiple Sclerosis Lesion Load on Fast FLAIR Imaging | American Journal of Neuroradiology, accessed July 17, 2025, https://www.ajnr.org/content/early/2022/07/28/ajnr.a7589
A Dynamic Network with Transformer for Image Denoising - MDPI, accessed July 17, 2025, https://www.mdpi.com/2079-9292/13/9/1676
MRI denoising using Deep Learning and Non-local averaging - arXiv, accessed July 17, 2025, https://arxiv.org/pdf/1911.04798
Heterogeneous window Transformer for image denoising - arXiv, accessed July 17, 2025, https://arxiv.org/html/2407.05709v2
A Deep Learning Framework for Denoising MRI Images using Autoencoders, accessed July 17, 2025, https://www.researchgate.net/publication/371562197_A_Deep_Learning_Framework_for_Denoising_MRI_Images_using_Autoencoders
image-domain deep-learning denoising technique for accelerated parallel brain MRI: prospective clinical evaluation | Radiology Advances | Oxford Academic, accessed July 17, 2025, https://academic.oup.com/radadv/article/1/3/umae022/7733581
(PDF) Boosting Magnetic Resonance Image Denoising With Generative Adversarial Networks - ResearchGate, accessed July 17, 2025, https://www.researchgate.net/publication/351005323_Boosting_Magnetic_Resonance_Image_Denoising_With_Generative_Adversarial_Networks
A review of deep learning in medical imaging: Imaging traits, technology trends, case studies with progress highlights, and future promises - PMC, accessed July 17, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC10544772/
Denoising of volumetric magnetic resonance imaging using multi-channel three-dimensional convolutional neural network with applications on fast spin echo acquisitions, accessed July 17, 2025, https://qims.amegroups.org/article/view/127018/html
Deep Learning Based Noise Reduction for Brain MR Imaging: Tests on Phantoms and Healthy Volunteers - PubMed Central, accessed July 17, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC7553817/
AI in medical imaging grand challenges: translation from competition to research benefit and patient care - PubMed Central, accessed July 17, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC10546459/
Generative Adversarial Networks: A Primer for Radiologists | RadioGraphics, accessed July 17, 2025, https://pubs.rsna.org/doi/full/10.1148/rg.2021200151
GANs with MRI Data - by Nandini Lokesh Reddy - Medium, accessed July 17, 2025, https://medium.com/@nandinilreddy/gans-with-mri-data-97e5f97f107c
How Artificial Intelligence Is Shaping Medical Imaging Technology: A Survey of Innovations and Applications - PMC, accessed July 17, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC10740686/
RCA-GAN: An Improved Image Denoising Algorithm Based on Generative Adversarial Networks - MDPI, accessed July 17, 2025, https://www.mdpi.com/2079-9292/12/22/4595
Zero-shot Low-field MRI Enhancement via Denoising Diffusion Driven Neural Representation - MICCAI, accessed July 17, 2025, https://papers.miccai.org/miccai-2024/paper/3647_paper.pdf
A Critical Analysis of Diffusion Models for Medical Image Denoising - MICCAI, accessed July 17, 2025, https://papers.miccai.org/miccai-2024/paper/2146_paper.pdf
On Instabilities of Unsupervised Denoising Diffusion Models in Magnetic Resonance Imaging Reconstruction - arXiv, accessed July 17, 2025, https://arxiv.org/html/2406.16983v1
Comparative Analysis of Noise Reduction Techniques for Body Fluid Image Enhancement | Request PDF - ResearchGate, accessed July 17, 2025, https://www.researchgate.net/publication/390219992_Comparative_Analysis_of_Noise_Reduction_Techniques_for_Body_Fluid_Image_Enhancement
A Generative Adversarial Network technique for high-quality super-resolution reconstruction of cardiac magnetic resonance images - PubMed, accessed July 17, 2025, https://pubmed.ncbi.nlm.nih.gov/34699953/
A Lightweight CNN-Transformer Implemented via Structural Re-Parameterization and Hybrid Attention for Remote Sensing Image Super-Resolution - MDPI, accessed July 17, 2025, https://www.mdpi.com/2220-9964/14/1/8
Zero-shot Low-field MRI Enhancement via Denoising Diffusion Driven Neural Representation | MICCAI 2024 - Open Access, accessed July 17, 2025, https://papers.miccai.org/miccai-2024/855-Paper3647.html
SwinIR: Image Restoration Using Swin Transformer - CVF Open Access, accessed July 17, 2025, https://openaccess.thecvf.com/content/ICCV2021W/AIM/papers/Liang_SwinIR_Image_Restoration_Using_Swin_Transformer_ICCVW_2021_paper.pdf
SwinIR: Image Restoration Using Swin Transformer (official repository) - GitHub, accessed July 17, 2025, https://github.com/JingyunLiang/SwinIR
Imaging Transformer for MRI Denoising: a Scalable Model ..., accessed July 17, 2025, https://www.microsoft.com/en-us/research/publication/imaging-transformer-for-mri-denoising-a-scalable-model-architecture-that-enables-snr1-imaging/
(PDF) Imaging Transformer for MRI Denoising: a Scalable Model Architecture that enables SNR << 1 Imaging - ResearchGate, accessed July 17, 2025, https://www.researchgate.net/publication/390811985_Imaging_Transformer_for_MRI_Denoising_a_Scalable_Model_Architecture_that_enables_SNR_1_Imaging
Transformer-based deep learning denoising of single and multi-delay 3D arterial spin labeling - PubMed, accessed July 17, 2025, https://pubmed.ncbi.nlm.nih.gov/37849048/
(ISMRM 2024) Deep learning enabled MRI general denoising at 0.55T, accessed July 17, 2025, https://archive.ismrm.org/2024/0874.html
(ISMRM 2024) Denoising very low field magnetic resonance images using native noise modeling and deep learning, accessed July 17, 2025, https://archive.ismrm.org/2024/2801.html
(ISMRM 2024) Imaging transformer for MRI denoising with SNR unit training: enabling generalization across field-strengths, imaging contrasts, and anatomy, accessed July 17, 2025, https://archive.ismrm.org/2024/0654.html
This is the official implementation of our proposed SwinMR - GitHub, accessed July 17, 2025, https://github.com/ayanglab/SwinMR
Noise2Noise MRI for High-resolution Diffusion-weighted Imaging of the Brain: Deep Learning-based denoising without need for Highly Averaged Ground-truth Images - ISMRM, accessed July 17, 2025, https://cds.ismrm.org/protected/19MProceedings/PDFfiles/3392.html
(PDF) Self‐supervised learning for denoising of multidimensional MRI data - ResearchGate, accessed July 17, 2025, https://www.researchgate.net/publication/381765764_Self-supervised_learning_for_denoising_of_multidimensional_MRI_data
Self-supervised learning for denoising of multidimensional MRI data, accessed July 17, 2025, https://pubmed.ncbi.nlm.nih.gov/38934408/
Deep Learning for Accelerated and Robust MRI Reconstruction: a Review - arXiv, accessed July 17, 2025, https://arxiv.org/html/2404.15692v1
Physics-informed deep neural network for image denoising - ResearchGate, accessed July 17, 2025, https://www.researchgate.net/publication/375679544_Physics-informed_deep_neural_network_for_image_denoising
(PDF) Physics Informed Neural Network Enhanced Denoising for Atomic Resolution STEM Imaging - ResearchGate, accessed July 17, 2025, https://www.researchgate.net/publication/387140834_Physics_Informed_Neural_Network_Enhanced_Denoising_for_Atomic_Resolution_STEM_Imaging
[Literature Review] A Physics-Informed Deep Learning Model for MRI Brain Motion Correction - Moonlight | AI Colleague for Research Papers, accessed July 17, 2025, https://www.themoonlight.io/en/review/a-physics-informed-deep-learning-model-for-mri-brain-motion-correction
Physics-informed neural networks for denoising high b-value ..., accessed July 17, 2025, https://pubmed.ncbi.nlm.nih.gov/40494002/
Physics-informed neural networks for enhancing medical flow magnetic resonance imaging: Artifact correction and mean pressure and Reynolds stresses assimilation - AIP Publishing, accessed July 17, 2025, https://pubs.aip.org/aip/pof/article-abstract/37/2/025194/3336391
A Physics-Informed Deep Learning Model for MRI Brain Motion Correction - PMC, accessed July 17, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC11844622/
[1911.04798] MRI denoising using Deep Learning and Non-local averaging - arXiv, accessed July 17, 2025, https://arxiv.org/abs/1911.04798
A Hybrid Approach for CT Image Noise Reduction Combining Method Noise-CNN and Shearlet Transform - Biomedical and Pharmacology Journal, accessed July 17, 2025, https://biomedpharmajournal.org/vol17no3/a-hybrid-approach-for-ct-image-noise-reduction-combining-method-noise-cnn-and-shearlet-transform/
Ways of cheating on popular objective metrics: blurring, noise, super-resolution and others, accessed July 17, 2025, https://videoprocessing.ai/metrics/ways-of-cheating-on-popular-objective-metrics.html
Image Quality Assessment through FSIM, SSIM, MSE and PSNR—A Comparative Study - Journal of Computer and Communications - SCIRP, accessed July 17, 2025, https://www.scirp.org/journal/paperinforcitation?paperid=90911
Performance comparison of different denoising methods on three benchmarks., accessed July 17, 2025, https://www.researchgate.net/figure/Performance-comparison-of-different-denoising-methods-on-three-benchmarks_tbl1_368842181
Benchmarking Deep Learning-Based Low-Dose CT Image Denoising Algorithms - arXiv, accessed July 17, 2025, https://arxiv.org/html/2401.04661v2
Deep learning-based denoising image reconstruction of body magnetic resonance imaging in children - PMC - PubMed Central, accessed July 17, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC12119730/
(PDF) Evaluating Second-Generation Deep Learning Technique for Noise Reduction in Myocardial T1-Mapping Magnetic Resonance Imaging - ResearchGate, accessed July 17, 2025, https://www.researchgate.net/publication/391890473_Evaluating_Second-Generation_Deep_Learning_Technique_for_Noise_Reduction_in_Myocardial_T1-Mapping_Magnetic_Resonance_Imaging
Evaluating Second-Generation Deep Learning Technique for Noise Reduction in Myocardial T1-Mapping Magnetic Resonance Imaging - PMC, accessed July 17, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC12110243/
Accelerating Whole-Body Diffusion-weighted MRI with Deep Learning–based Denoising Image Filters - PubMed Central, accessed July 17, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC8489468/
(PDF) Comparative Study of Traditional and Deep-Learning Denoising Approaches for Image-Based Petrophysical Characterization of Porous Media - ResearchGate, accessed July 17, 2025, https://www.researchgate.net/publication/358088510_Comparative_Study_of_Traditional_and_Deep-Learning_Denoising_Approaches_for_Image-Based_Petrophysical_Characterization_of_Porous_Media
Comparative Study of Traditional and Deep-Learning Denoising Approaches for Image-Based Petrophysical Characterization of Porous Media - Frontiers, accessed July 17, 2025, https://www.frontiersin.org/journals/water/articles/10.3389/frwa.2021.800369/full
Enhancing Radiologist Productivity with Artificial Intelligence in Magnetic Resonance Imaging (MRI): A Narrative Review - MDPI, accessed July 17, 2025, https://www.mdpi.com/2075-4418/15/9/1146
Challenges of deep learning in medical image analysis – improving explainability and trust - CentAUR, accessed July 17, 2025, https://centaur.reading.ac.uk/109789/1/Challenges%20of%20Deep%20Learning%20in%20Medical%20Image%20Analysis%20%E2%80%93%20Improving%20Explainability%20and%20Trust%20_%20Full%20Text.pdf
AI-Powered Object Detection in Radiology: Current Models, Challenges, and Future Direction - MDPI, accessed July 17, 2025, https://www.mdpi.com/2313-433X/11/5/141
Clinical Impact of Deep Learning Reconstruction in MRI | RadioGraphics - RSNA Journals, accessed July 17, 2025, https://pubs.rsna.org/doi/full/10.1148/rg.220133
kondratevakate/mri-deep-learning-tools - GitHub, accessed July 17, 2025, https://github.com/kondratevakate/mri-deep-learning-tools
mrphys/sodium_MRI_DnCNN: Example code for training a denoising convolutional neural network (DnCNN) for MRI - GitHub, accessed July 17, 2025, https://github.com/mrphys/sodium_MRI_DnCNN
Deep learning denoising reconstruction for improved image quality in fetal cardiac cine MRI, accessed July 17, 2025, https://www.frontiersin.org/journals/cardiovascular-medicine/articles/10.3389/fcvm.2024.1323443/full
denoising · GitHub Topics, accessed July 17, 2025, https://github.com/topics/denoising
cszn/DnCNN: Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising (TIP, 2017) - GitHub, accessed July 17, 2025, https://github.com/cszn/DnCNN
A Review of Electromagnetic Elimination Methods for low-field portable MRI scanner - arXiv, accessed July 17, 2025, https://arxiv.org/html/2406.17804v1
A Systematic Review and Identification of the Challenges of Deep Learning Techniques for Undersampled Magnetic Resonance Image Reconstruction - MDPI, accessed July 17, 2025, https://www.mdpi.com/1424-8220/24/3/753
Deep learning methods for 3D magnetic resonance image denoising, bias field and motion artifact correction: a comprehensive review - PubMed, accessed July 17, 2025, https://pubmed.ncbi.nlm.nih.gov/39569887/
Using Deep Learning to Simultaneously Reduce Noise and Motion Artifacts in Brain MR Imaging - J-Stage, accessed July 17, 2025, https://www.jstage.jst.go.jp/article/mrms/advpub/0/advpub_mp.2024-0098/_article
(PDF) Deep learning methods for 3D magnetic resonance image denoising, bias field and motion artifact correction: a comprehensive review - ResearchGate, accessed July 17, 2025, https://www.researchgate.net/publication/386023151_Deep_learning_methods_for_3D_magnetic_resonance_image_denoising_bias_field_and_motion_artifact_correction_a_comprehensive_review